PROCESO DE CALIFICACIÓN (SCORE) DE ABANDONO.
La calificación del abandono de cliente, se enmarcará en el modelo CRISP-DM (creado en 2000 por SPSS, NCR y Daimer Chrysler), que estructura el proceso de minería de datos en seis fases: Comprensión del negocio, Comprensión de los datos, Preparación de los datos, Modelado, Evaluación e Implantación.
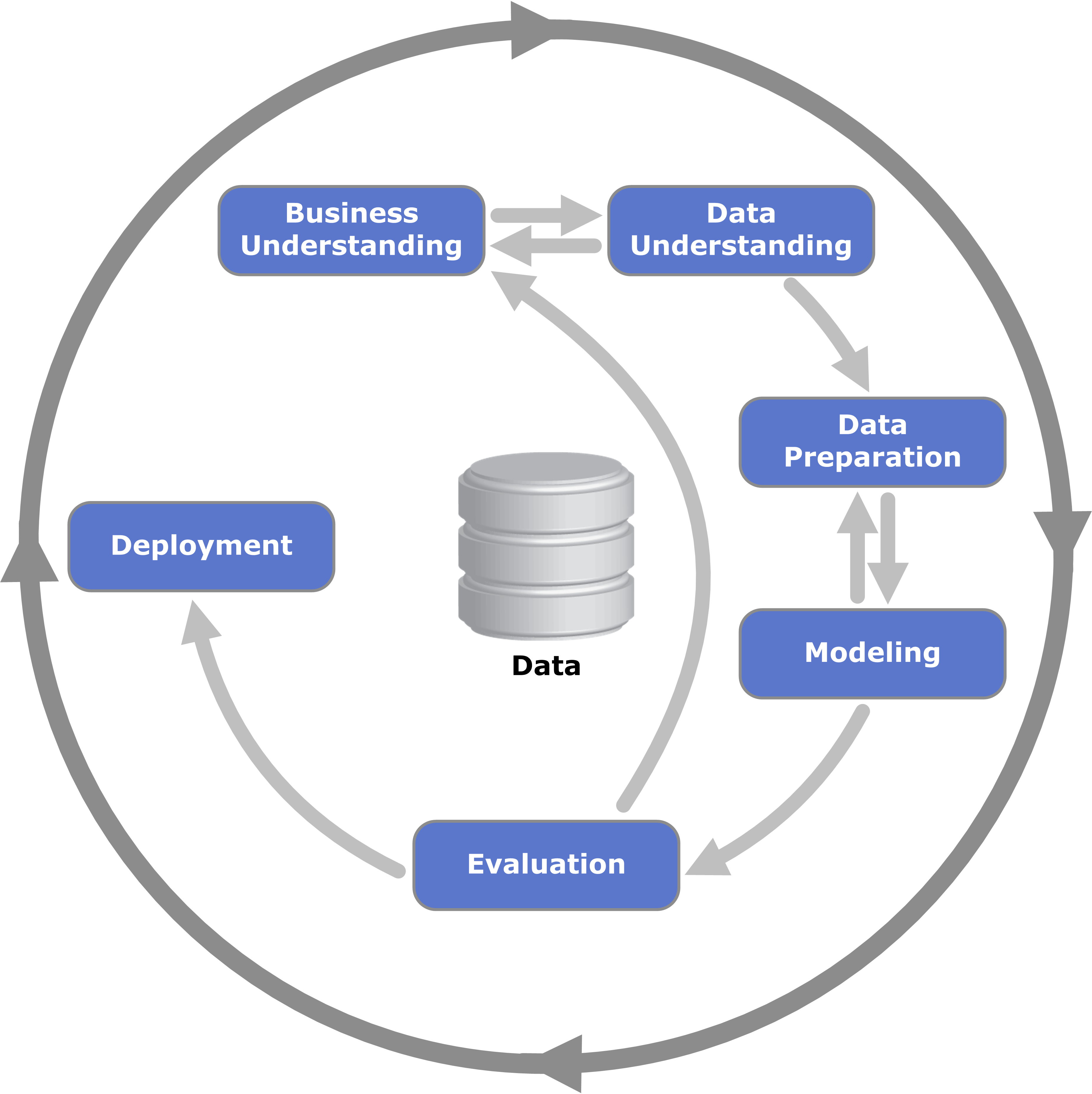
FUENTE: https://upload.wikimedia.org/wikipedia/commons/b/b9/CRISP-DM_Process_Diagram.png
COMPRENSIÓN DEL NEGOCIO
En la fase de entendimiento de negocio, una pregunta primordial es ¿qué se entiende por abandono del cliente para este negocio?, no siempre es obvio este indicador, por ejemplo, la no renovación de un contrato es un claro indicador de abandono del cliente, pero ¿y si no tiene contrato?, entonces se deberá tomar un criterio claro de lo que significa o como sé que me abandonaron, tratando de puntualizar, “llevan un mes sin comprar, dos meses, o 15 días, está a 3 desviaciones estándar del promedio de sus días de compra, etc.”. Entender la naturaleza del negocio nos ayudará a tener una buena definición de abandono de cliente. La característica que determina si un cliente abandona, constituirá lo que se conoce como “variable objetivo”.
COMPRENSIÓN DE LOS DATOS
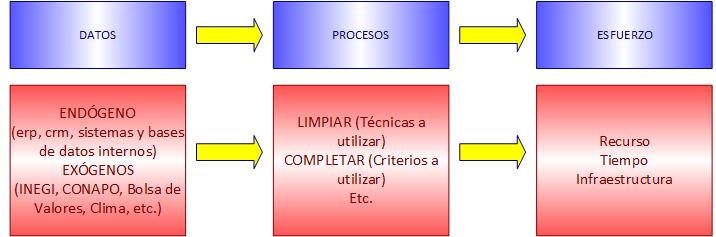
En esta fase se resolverá la pregunta ¿con qué datos cuenta el negocio que le ayuden a detectar el por qué lo abandonan sus clientes?, se recaban los datos (endógenos y exógenos) con que cuenta el negocio o que se pueden obtener, y se sospecha que pueden explicar el abandono de clientes. Los entendemos, es decir revisamos el formato en que están, de que tipo son (números, texto, logs, etc.), si están completos, “limpios”, etc.
Por ejemplo, se pide información de los clientes, su comportamiento transaccional, en donde están ubicados (código postal p.ej.), en que sucursal compran, información de los sistemas (CRM, ERP, encuestas, quejas, etc.), datos del entorno como perturbaciones del mercado (cambio de precio, de servicio, competencia, tipo de cambio, etc.). Medir el esfuerzo de esta fase, será de gran utilidad para tener expectativas reales (tiempo, recursos, infraestructura, etc).
PREPARACIÓN DE LOS DATOS
La primer tarea de esta fase es limpiar, completar, y formatear adecuadamente los datos, para generar una gran tabla que contenga los datos de todas las variables recabadas, asegurándonos de que todos los campos tienen valores válidos, están completos y tiene una representación adecuada para poderlos ingresar a los algoritmos que utilizaremos. Este es uno de los procesos que más tiempo puede llevar, sobre todo porque implica limpiar los datos y lo que esto representa (VER ARTÍCULO DE LIMPIEZA DE DATOS). Esta “gran tabla” construida, se conoce como un ABT (Analytics Base Table).
Con la ABT construida, nos damos a la tarea de explorar los datos para poder conocer como se comportan, para ello podemos utilizar herramientas de inteligencia de negocio que pueden facilitar enormemente la tarea y herramientas cómo R y Phyton para algoritmos de ciencia de datos, en el caso del vídeo al final del artículo utilizamos QlikView que es una herramienta fácil de utilizar y ademas podemos obtener una versión personal totalmente gratis en su página oficial.
Este análisis exploratorio nos servirá para determinar el tipo de estadística a utilizar (paramétrica o no paramétrica), también ayudará determinar el conjunto de variables que explican el fenómeno, en este paso buscaremos minimizar los falsos negativos (es decir minimizar la probabilidad de eliminar una variable que pensamos que no explica el abandono, cuando en realidad si lo explica), cómo se comportan estas variables (frecuencia, periodicidad, etc.). Entre las variables elegidas buscamos aquellas que sean “independiente entre sí”, con la finalidad de contar con un conjunto reducido de variables que explique al menos el 75% de la varianza, esto se puede realizar utilizando técnicas de análisis de componentes principales.
Es buena estrategia utilizar algún algoritmo no supervisado para tratar de tener alguna clasificación de nuestros clientes, en este caso por ejemplo mostramos un resultado utilizando el monto de la compra, su frecuencia y la fecha de la última compra:
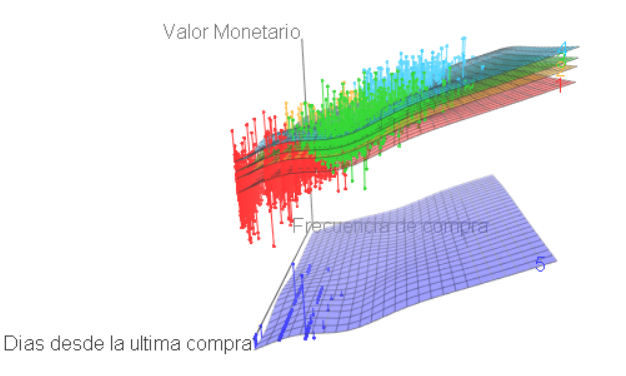
Etiquetando las clasificaciones obtenidas aplicando en este caso un algoritmo de clúster a los datos de los clientes, estamos preparados para mostrarlo como datos legibles para el usuario final, como se muestra a continuación:
|
Segmento |
Valor monetario |
Frecuencia de compra |
Días desde la última compra |
|
Oro |
$214,755 |
54 |
17 |
|
Plata |
$27,440 |
10 |
42 |
|
Bronce |
$55,535 |
17 |
477 |
|
Sin valor |
$5,000 |
2 |
863 |
MODELADO
Ahora si estamos preparados y nos damos a la tarea de construir los modelos que predigan el abandono de cliente, nótese el uso del plural, ya que no es un único modelo el que obtendremos y esto estará en función de cómo segmentemos los datos, por ejemplo, por periodos (semestral, trimestral, etc.). Es importante elegir una manera clara de cómo presentar las características que influyen en el abandono del cliente. Por ejemplo, un modelo que explica el abandono de cliente se podría presentar como en la siguiente imagen:
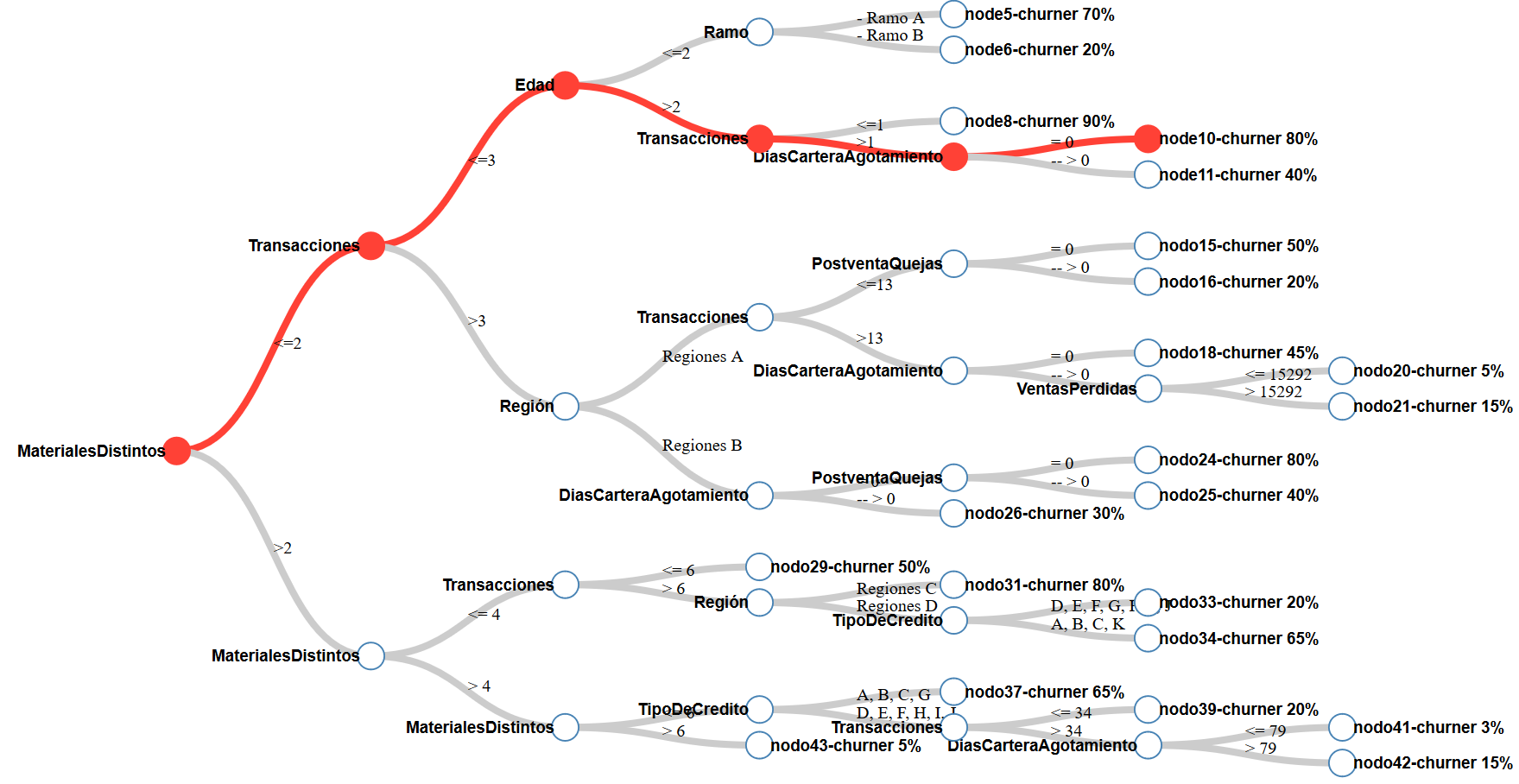
La ruta roja, nos muestra que los clientes que compran solo un producto, realizan dos o tres transacciones, han estado con nosotros por más de dos años y tienen más de un día de cartera de agotamiento, NOS ABANDONARAN con un 80% de probabilidad.
EVALUACIÓN
En esta fase responderemos a la pregunta ¿qué tan preciso y exacto son los modelos construidos?
Validar un modelo consiste en contrastar sus predicciones respecto a datos considerados independientes para obtener una medida de 1) su significancia en relación con una cierta hipótesis nula, o 2) su desempeño (capacidad de clasificar correctamente nuevos datos).
IMPLANTACIÓN
Una vez validado los modelos, es buena estrategia mostrar en datos “duros” que significa este abandono para la toma de decisiones. Algunos indicadores importantes para esto son: ¿cuántos clientes cumplen con las condiciones de abandono?, ¿cuánto representa su compra?, si los hubiera conservado ¿cuánto dinero hubiera ingresado?, si los contacto ¿en cuanto puedo reducir el abandono?, esta última información justifica los esfuerzos de la ciencia de datos. Estas preguntas se debieran responder de manera intuitiva en la fase Implantación del modelo. En el video a continuación muestra el uso de Qlik como herramienta de Inteligencia de negocios, el cual nos permite mostrar los resultados de este análisis, esto es lo que nosotros llamamos BI con esteroides.