LIMPIEZA DE DATOS
Los datos se han puesto de moda, actualmente son el centro de los grandes acontecimientos de cómputo, por ejemplo, se hace referencia a ellos cuándo se habla del “Big Data”, de la minería de datos, el “machine learning” y su visualización. De pronto todo mundo parece estar interesado en la “Ciencia de datos”, desde los que trabajan en el área de la estadística, los desarrolladores de software, incluso los diseñadores gráficos. El abaratamiento del hardware, el mejoramiento de las herramientas de procesamiento y visualización de grandes cantidades de información, los datos abiertos, etc., da la oportunidad a un mayor número de personas de beneficiarse con el descubrimiento de patrones y estar en posibilidad de realizar predicciones con mayor precisión, de manera fácil y barata (siempre y cuando se tenga el conocimiento).
Sin embargo, la gran mercadotecnia alrededor de lo datos, casi no habla de que toda esta gran esperanza y sueño que promete la ciencia de datos, se basa en el supuesto de que se tienen datos adecuados y “limpios”, pero que antes estaban “sucios”, y que para que puedan ser considerados como materia prima esencial de la ciencia de datos, se tienen que transformar, comprimir, limpiar, mover varias veces, es entonces cuando están listos para ser utilizados en los algoritmos y poderlos visualizar.
UNA PERSPECTIVA RECIENTE
El “The New York Times” llamó a la limpieza de datos un trabajo de “talacha”, ya que al menos el 80% del tiempo de un científico de datos lo utiliza en este proceso. Sin embargo, a pesar de su importancia y el esfuerzo que representa, los impulsores de la “fiebre” de los datos no le conceden la misma importancia que a la tecnología del Big Data, la minería de datos o el aprendizaje automático. La siguiente figura muestra el comparativo de la importancia concedida a algunas de las tareas principales de la ciencia de datos.
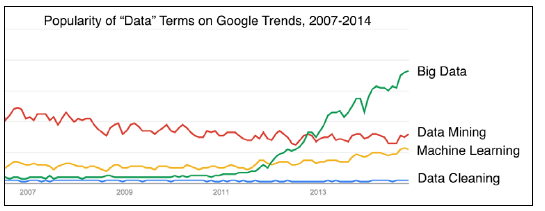 Relevancia concedida a los procesos de ciencia de datos
Relevancia concedida a los procesos de ciencia de datos
El trabajo que implica la limpieza de datos, llega a ser engorroso, lo que lo convierte en una labor poco atractiva o interesante, la mayoría de los científicos de datos, saben que tienen que hacer esta tarea lo antes posible en lugar de ignorarlas, quejarse o darle sobrenombres degradantes.
LOS PROCESOS DE LA CIENCIA DE DATOS
Pero, ¿Cuál es la importancia de la limpieza de datos en el trabajo de la ciencia de datos?
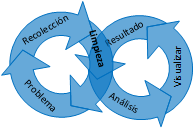
Bueno, la respuesta corta es que es una pieza fundamental, y que afecta directamente a los procesos que vienen antes y después de ella. La respuesta larga se basa en describir los seis pasos de que se compone la ciencia de datos. Como se muestra en la siguiente imagen, la limpieza de datos está justo a la mitad, en el paso 3.
 Procesos de ciencia de datos
Procesos de ciencia de datos
Sin embargo, en lugar de pensar en estos pasos como un marco de trabajo lineal, de inicio – fin, en un proyecto veremos que pasaremos varias veces por ellos de una manera iterativa. Esto depende de las necesidades del proyecto en particular.
 Procesos de ciencia de datos desde la perspectiva de datos infinitos
Procesos de ciencia de datos desde la perspectiva de datos infinitos
- El primer paso es entender el enunciado del problema. Identificar cuál es el problema que se está tratando de resolver.
- El siguiente paso es la recolección y almacenamiento de datos. ¿De dónde proceden los datos que ayudarán a resolver el problema? ¿Dónde se almacenan y en qué formato?
- Entonces viene la limpieza de datos. ¿Hizo algún cambio en los datos? ¿Se ha borrado algo? ¿Cómo se prepararon para el análisis y la minería de datos?
- El siguiente paso es el análisis de datos y el aprendizaje automático. ¿qué tipos de procesamientos se hicieron a los datos? ¿Qué transformaciones? ¿Cuáles algoritmos se usaron? ¿Qué formulas se aplicaron? ¿Cuáles algoritmos de aprendizaje automático se utilizaron? ¿En qué orden?
- Lo que sigue es la representación y visualización. ¿Cómo se muestran los resultados del trabajo realizado? ¿Son una o más tablas, gráficas, diagramas de red, nube de palabras, etc.? ¿Es la mejor visualización para representar los datos? ¿Cuáles alternativas se consideraron?
- El último paso es la resolución del problema. ¿Cuál es la respuesta al problema o pregunta que se plateo en el paso 1? ¿Cuáles limitaciones tiene sobre sus resultados? ¿Hubo partes del problema que no se podían responder con este método? ¿Qué se pudo haber hecho de otra forma? ¿Cuáles son los pasos a seguir?
De lo anterior, se deriva que tiene sentido que la limpieza de los datos se debe hacer antes de intentar el análisis, minería, aprendizaje automático o la visualización. Aunque, debemos recordar que esto es un proceso iterativo, por lo que posiblemente se tendrá que volver a limpiar los datos varias veces durante el curso de un proyecto. Por otro lado, las técnicas de minería y análisis seleccionado a menudo nos indicarán la manera de limpiar los datos. La limpieza de datos incluye una variedad de tareas que son establecidas por el método de análisis elegido, por ejemplo, el intercambio de formatos de archivos, el cambio de codificación de caracteres o el análisis de parte de los datos.
La limpieza de los datos está muy ligada al paso dos de recolección y almacenamiento de datos. Esto significa que tal vez tenga que recolectar los datos en bruto, almacenarlos, limpiarlos, almacenar los datos limpiados, recolectar un poco más de datos, que se limpian y se combinan con los datos anteriores, limpiar de nuevo y almacenarlos, así sucesivamente. Por lo que es muy importante poder recordar lo que se hizo y ser capaz de repetir el proceso de nuevo si es necesario o decirle a otra persona lo que se hizo.
Bibliografía
Squire, M. (2015). Clean Data. Packt.